DIRB is a web content scanner that plays a crucial role in the process of web penetration testing and vulnerability assessment. Its primary function is to discover hidden directories and files on a web server by brute-forcing a given URL using a wordlist. Web servers often host sensitive directories and files that may not be explicitly linked or accessible through a browser, such as configuration files, backup files, or admin panels. DIRB helps security testers by automating the process of discovering these resources, which could potentially expose a server to unauthorized access or information disclosure.
DIRB is particularly useful in the context of assessing the security posture of a web server by identifying unintended files or directories that should be restricted or protected. Although it is a powerful tool, it does not directly exploit vulnerabilities; rather, it reveals possible attack vectors that a malicious actor might exploit. The tool is typically used in conjunction with other scanning tools and manual testing techniques to perform comprehensive web security assessments.
How DIRB Works
DIRB operates based on a dictionary attack principle, where it sends requests to a target web server using different directory and file names. It systematically tries these potential locations to see if they exist or return a response from the server. The core of its operation revolves around the following steps:
- Target Specification: The user defines the target URL or domain they want to scan. This URL could represent the homepage of a website, an application server, or any web resource. For instance, if the target is http://example.com, DIRB will attempt to find hidden directories and files associated with that domain.
- Wordlist Utilization: DIRB relies on wordlists to perform its scans. These wordlists contain a set of directory and file names that the tool will use to brute-force the web server. DIRB comes with default wordlists, but users can also provide custom wordlists, tailored for specific environments or targets. The wordlists contain common directory names such as admin/, login/, backup/, and filenames like config.php or index.html. By sequentially appending these names to the target URL, DIRB sends requests to the server to check for their existence.
- HTTP Response Handling: For each request that DIRB sends, it analyzes the server’s HTTP response. There are different possible outcomes:
- HTTP 200 (OK): This means that the directory or file exists, and DIRB will flag it as a potential finding.
- HTTP 403 (Forbidden): Even if access is forbidden, this response indicates the directory or file exists but is restricted, so it is also flagged as significant.
- HTTP 404 (Not Found): This indicates that the file or directory does not exist, and DIRB moves on to the next entry in the wordlist.
- Other HTTP Status Codes: These may also provide useful information, such as redirects or server errors, which DIRB logs for further analysis.
- Recursive Scanning: DIRB has an option for recursive scanning, where once it finds a directory, it continues to brute-force subdirectories within it. For example, if it discovers http://example.com/admin/, it will proceed to scan inside the admin/ directory for more hidden files and folders.
- Extension-based Scanning: Another key feature of DIRB is its ability to handle file extensions. By appending common file extensions like .php, .html, .txt, or .bak, DIRB can also search for specific files that may have been inadvertently left on the server.
- Logging and Output: DIRB generates detailed logs of its scan results, highlighting which directories or files were found, along with the associated HTTP responses. This output can be analyzed further to determine the sensitivity of the discovered resources.
Limitations and Best Practices
While DIRB is a powerful tool, it does have limitations. Since it relies on wordlists, its effectiveness is highly dependent on the quality and relevance of the wordlist being used. If important directories or files are named in a non-standard way (i.e., they are not present in the wordlist), DIRB may not find them. Additionally, large wordlists or recursive scanning can generate a significant number of requests, which could lead to detection by web server defenses or rate-limiting.
To maximize DIRB’s effectiveness, it should be used in conjunction with other tools and manual investigation. Proper selection of wordlists and understanding the context of the target system are essential for producing meaningful results.
Let’s start our practical on DIRB :-
-a <agent_string> : Specify your custom USER_AGENT.
-c <cookie_string> : Set a cookie for the HTTP request.
-f : Fine tunning of NOT_FOUND (404) detection.
-H <header_string> : Add a custom header to the HTTP request.
-i : Use case-insensitive search.
-l : Print “Location” header when found.
-N <nf_code>: Ignore responses with this HTTP code.
-o <output_file> : Save output to disk.
-p <proxy[:port]> : Use this proxy. (Default port is 1080)
-P <proxy_username:proxy_password> : Proxy Authentication.
-r : Don’t search recursively.
-R : Interactive recursion. (Asks for each directory)
-S : Silent Mode. Don’t show tested words. (For dumb terminals)
-t : Don’t force an ending ‘/’ on URLs.
-u <username:password> : HTTP Authentication.
-v : Show also NOT_FOUND pages.
-w : Don’t stop on WARNING messages.
-X <extensions> / -x <exts_file> : Append each word with this extensions.
-z : Add a milliseconds delay to not cause excessive Flood.
Utilizing Multiple Wordlist for Directory Traversing
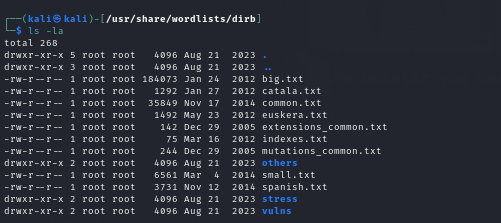
The default wordlist_files common.txt is used in the aforementioned attack; however, we have the option to modify this word list and use a different wordlist for directory traversal. To view all of the wordlists that are available, you must take the following route.
cd /usr/share/wordlists/dirb
ls –la
cd /usr/share/wordlists/vulns
ls –la

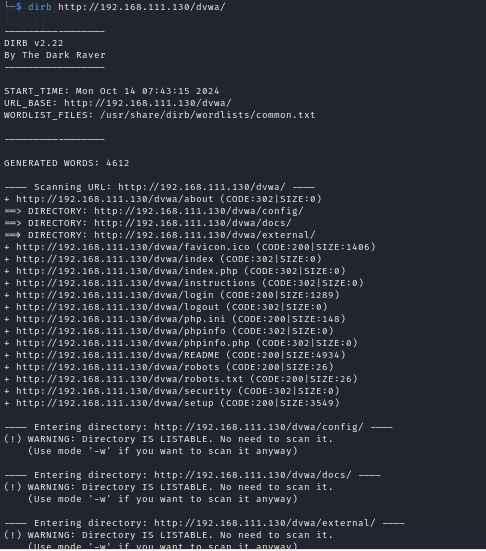
Default working of dirb
The protester can use the following command in this attack since common.txt is configured as the default word list for directory traversal. To initiate the Brussels Directory attack, open the terminal and enter the following command.
Command:-dirb http://192.168.1.106/dvwa/
Listing Directories with Particular Extension Lists:-
We can utilize the -X argument of the dirb scan in many cases where we need to extract the directories of a particular extension over the target server. Once the file extension name has been accepted, this parameter searches the destination server or computer for the specified extension files.
As seen in the following screenshot, the aforementioned operation will extract every directory path associated with the PHP extension.
- command:-Dirb http://192.168.111.130/dvwa/login.php
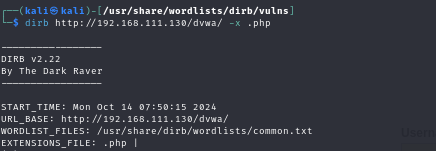
Save output to DISK
We save the dirb scan’s output to a file for future reference, improved readability, and record keeping. To do this, we will utilize the dirb scan’s -o parameter, which allows us to store the results in a text file.
- dirb http://192.168.111.130/dvwa/ -o open.txt
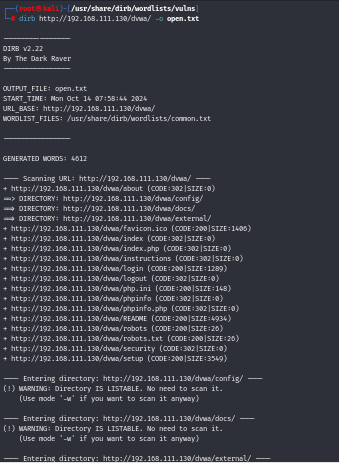
The command has now been successfully run; let us now navigate to the destination to verify if the output has been saved to the file. Here, /output.txt is where we store the output.
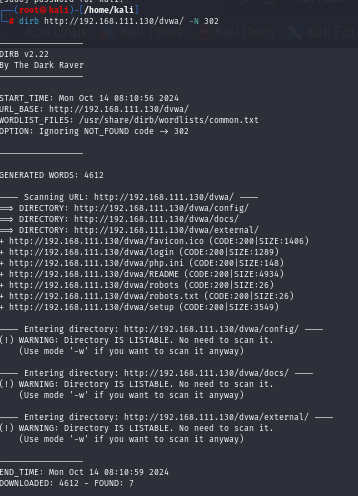
IGNORE UNNECESSARY STATUS-CODE
The Status-Code element is a three-digit integer, with the first number designating the response’s class and the final two digits serving no classification purpose. As seen here, we are employing the -N argument on code 302 in this attack.
COMMAND:- dirb http://192.168.111.130/dvwa/ -N 302
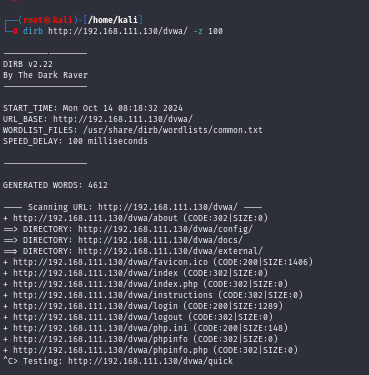
SPEED DELAY
When working in various settings, we occasionally encounter surroundings that are unable to withstand the deluge that the dirb scan creates. In these situations, it is crucial to postpone the scan for a while. The -z argument of the dirb scan makes this simple. Milliseconds are used to represent the time in this parameter. As demonstrated in our example, we have set the dirb to a 100-second delay.
- dirb http://192.168.1.106/dvwa -z 100